
ISPD 2010 High Performance Clock Network Synthesis Contest
[News and Announcements].
[Introduction].
[Schedule].
[Evaluation and Ranking].
[Input/Output Format].
[Evaluation Script].
[Join the Contest].
[Submission Guideline].
[Terms and Conditions]
News and Announcements
- Apr 15, 2009 (THU): Fixed an error in the result slides. CPU time of team 09 was wrong for the first two benchmarks.
- Mar 29, 2009 (MON): Contest results and simulation files can be download at
here. It contains all benchmarks and the latest evaluation script.
- Mar 16, 2009 (TUE): Contest results have been released in contest today.
Slides (with detailed final results) can be downloaded at
here. All benchmarks and results
files will be posted in this page soon. Please check back.
- Dec 6, 2009 (SUN): Detailed rules are posted, which includes the
new evaluation script eval2010.pl. Please note that this is the first
draft and updates will be made to eval2010.pl if there is any error.
- Nov 30, 2009 (MON): Detailed rule will be posted by December
6,2009(SUN). Please check this website for any update.
- Nov 30, 2009 (MON): So far 14 teams have registered. Since it is just
after DAC submission and the thanksgiving long vacation, we would like to
postpone the registration deadline by a week. If you would like to
participate, please send an email by December 7, 2009.
- Oct 19, 2009 (MON): Webpage is created announcing the new CNS contest.
This page will be updated with more details in November 2009.
Introduction
Continuing the tradition of spirited competition, the ISPD 2010 Steering Committee is pleased to
announce a clock distribution network synthesis contest. Like the prior
placement, routing and clocking contests, a set of benchmarks will be released; teams
are invited to derive algorithms for a practical clock distribution network
construction problem, with the best results winning fame, recognition, and a
grand prize.
Call for Participation
For the contest announcement and call for participation, please see
pdf and
txt.
Schedule
-
Oct 19, 2009: Announcement of the Contest
-
Dec 7, 2009: Last day to confirm participation with Dr. Cliff Sze (csze@us.ibm.com).
-
Jan 10, 2010: Each team must submit an alpha-version executable and a
script to test running it on our platforms. This is very important to make
sure that our simulation results match yours.
-
Feb 1, 2010: Final day to submit the final-version binary for your clock
tools, and results. (Time: 23:59 CST, UTC-6). A one-page description of
your algorithm must be attached with your final submission.
-
Mar 16, 2010: ISPD2010 - results announcement and prizes giving
Tool Evaluation and Ranking
-
We will use the open-sourced ngspice to simulate your clock distribution
network and calculate the clock latency. Please download ngspice from here and compile it in your own
system. You have to download the source code (the download filename must be
ng-spice-rework-19.tar.gz or ng-spice-rework-20.tar.gz.)
-
After you un-tar the package, you can find the documentation at
"ng-spice-rework-19/doc/ngspice.pdf". You have to make sure how to use this
simulator because you may need to try your solution (or subsets of your
clock distribution network) without using the official script.
- The contest will base on 45nm technology. We will use the PTM model card
with minimal change to be used in the ngspice environment. For more
information about PTM, please visit their official website at here.
-
We assume the clock source is at (0,0) which is the bottom left corner.
-
We assume an inverter will be placed exactly at clock source. The example
spice model of the inverter is here and it is
based on this model card. Using this two
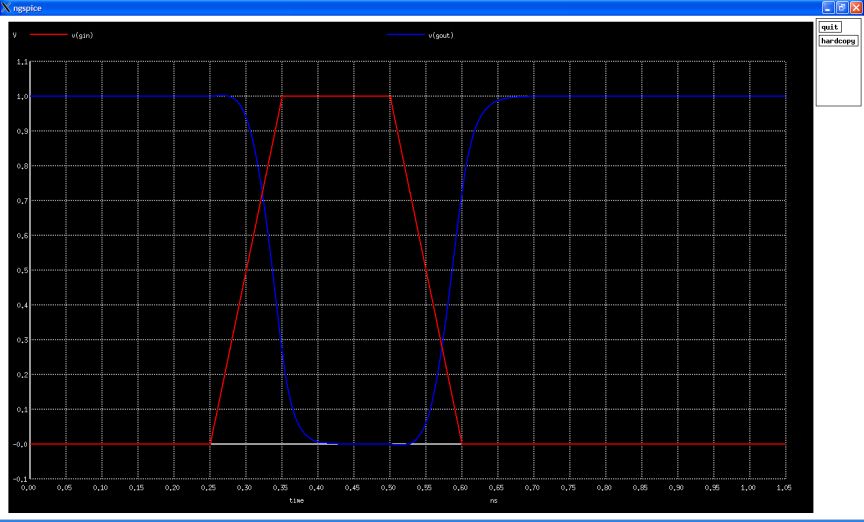
files by the command "ngspice -b clkinv1.spice", you will get this result. The corresponding plot will look like this.
-
The clock source inverter will be "automatically" added by the translator
script. So, your tool can assume an inverted signal from the source (driven
by the inverter). The inserted clock source inverter will be defined in
the input file. The input slew to this clock source inverter is always
100ps.
-
We will provide a couple buffer/inverter types for constructing the clock
distribution network. The buffer/inverter type will be similar to this(the .subckt part). Of course, you can connect
more than one inverter in parallel and the structure will give you a higher
drive strength. A figure of parallel connected inverters can be found here.
-
The clock distribution network does not have to be a tree. Once again,
buffers/inverter connected in parallel, or mesh/grid/cross-link structures
are allowed. Of course, you can connect two nodes with more than one wire
in parallel to reduce the resultant wire resistance. However, we enforce a
power-limit to all the solutions. Examples of inverters-in-parallel and
wires-in-parallel can be found in the sample output file
"ispd10cnsSample.out" inside the starter kit.
-
We assume the clock frequency is 2GHz with clock period of 500ps. Slew
(10%-90%) limit is 100ps.
-
We will provide a translator to convert from the output file format to
spice input file. The interconnect will be formulated with Pi-model. Long
interconnect will be segmented in advance.
-
Two type of wires will be available: wide wire (0.1 Ohms/um, 0.2 fF/um),
narrow wire (0.3 Ohms/um, 0.16 fF/um). On-chip variation upon wires will be
formulated.
-
The clock signal arriving the clock sinks must be "non-inverted". In other
words, there must be even number of inverters along the path from the clock
source to each clock sink. This is including the compulsory single inverter
we add to the clock source.
-
There are placement blockages in the layout while there are NO wiring
blockages. In other words, no buffer/inverter can be placed on top of any
blockage we provided but routing can be done over it.
-
Buffer/inverter placement will be formulated as a "point", which is a
single x,y location. This represents the buffer input/output pins. As a
result, the input pin and output pin must have the same coordinates when
you route the input/output nets of the buffer/inverter. Since the
buffer/inverter placement model is a point, you only have to make sure such
point is not covered by any placement blockage provided.
-
We will account for process variation in this contest. Simplified Monte
Carlo simulation will be used to account for vdd and wire variations.
-
For each benchmark, a nominal voltage and its variation settings will be
provided in the input file.
-
Local clock skew (LCS) is the clock skew between any two sinks with
distance less than or equal a threshold (e.g. 600nm). Assume si and sj are
two clock sinks; arr() denotes the clock arrival time and distance() denotes
the Manhattan distance between two clock sinks.
In other words, worst_LCS = max ( abs( arr(si) - arr (sj) ) ), \forall
si,sj \in ALL_SINKS AND distance(si,sj) is less than or equal to the
threshold.
-
There will be a worst LCS limit listed in each benchmark.
-
Although using I,V curve from SPICE simulation to estimate power would be
more accurate, it is easier and faster to use the CVVf equation to estimate
average power. As a result, we will use total interconnect and inverter
capacitance as a measurement of power. We will provide a total capacitance
limit in the input file of each benchmark.
-
For each inverter type, we will provide the input capacitance and output
parasitic capacitance for total capacitance calculation. All the
information will be provided in the input file.
Ranking
The clock distribution network solutions will be evaluated on the following
metrics:
-
The final rank of a clock network synthesis tool will be determined by the sum of
individual ranks of circuits. The smallest rank number wins the contest.
-
For each benchmark, the solution without slew violation, without local clock skew
violation, among all simulations, and with smallest power (in terms
of capacitance limit) will win.
-
If two solutions have the same power value, we will use worst local clock
skew as the tie-breaker.
-
If two solutions have the same total capacitance and the same worst local skew
value, we will use CPU-time as the second tie-breaker. CPU-time is the total
running time of your clock network synthesis tool in our dedicated Linux
machine.
-
The runtime limit is set to 12 hours. If a clock
network synthesis tool executable takes more than 12 hours to complete a
benchmark, it will be considered to be failed. CPU information of the Linux
machine can be found in this file.
We work hard to make sure the input/output format is as simple as possible.
The detailed description of the input/output format can be found in this
text file.
Small sample input/output files
Here are a sample input file and a sample output file of a simple 7-sink
clock network synthesis problem, with illustrations.
[Input],
[Output],
[Explanation].
Evaluation Script
Join the Contest
If you are interested in participating in the contest, or even if you
have any question, please feel free to send an email to Dr. Cliff Sze (csze@us.ibm.com).
To ensure prompt response, please start with "ISPD2010-CNS" in the subject of your email.
CONTESTANTS
Details will be announced in January 2010.
Submission Guideline
Final submission time is set to (Feb 1) 11:59pm CST(UTC-6), which corresponds to,
for example,
-
9:59pm (Feb 1) in California,
-
2:59pm (Feb 2) in Beijing, Taipei and Hong Kong,
-
7:59am (Feb 2) in Hannover, Germany.
You can send me an http-link such that I can download your binary (or source
files), scripts, clock network synthesis result files and a one-page algorithm
description from the link. Please zip or gtar all files.
Terms and Conditions
Sponsors
The contest is sponsored in part by ACM SIGDA and Intel Corporation
{kind=link}
{kind=link}